備註
您正在閱讀開發版本的文件。對於最新發行的版本,請參見 Kilted。
Executors
概覽
Execution management in ROS 2 is handled by Executors. An Executor uses one or more threads of the underlying operating system to invoke the callbacks of subscriptions, timers, service servers, action servers, etc. on incoming messages and events. The explicit Executor class (in executor.hpp in rclcpp, in executors.py in rclpy, or in executor.h in rclc) provides more control over execution management than the spin mechanism in ROS 1, although the basic API is very similar.
In the following, we focus on the C++ Client Library rclcpp.
Basic use
In the simplest case, the main thread is used for processing the incoming messages and events of a Node by calling rclcpp::spin(..) as follows:
int main(int argc, char* argv[])
{
// Some initialization.
rclcpp::init(argc, argv);
...
// Instantiate a node.
rclcpp::Node::SharedPtr node = ...
// Run the executor.
rclcpp::spin(node);
// Shutdown and exit.
...
return 0;
}
The call to spin(node) basically expands to an instantiation and invocation of the Single-Threaded Executor, which is the simplest Executor:
rclcpp::executors::SingleThreadedExecutor executor;
executor.add_node(node);
executor.spin();
By invoking spin() of the Executor instance, the current thread starts querying the rcl and middleware layers for incoming messages and other events and calls the corresponding callback functions until the node shuts down.
In order not to counteract the QoS settings of the middleware, an incoming message is not stored in a queue on the Client Library layer but kept in the middleware until it is taken for processing by a callback function.
(This is a crucial difference to ROS 1.)
A wait set is used to inform the Executor about available messages on the middleware layer, with one binary flag per queue.
The wait set is also used to detect when timers expire.
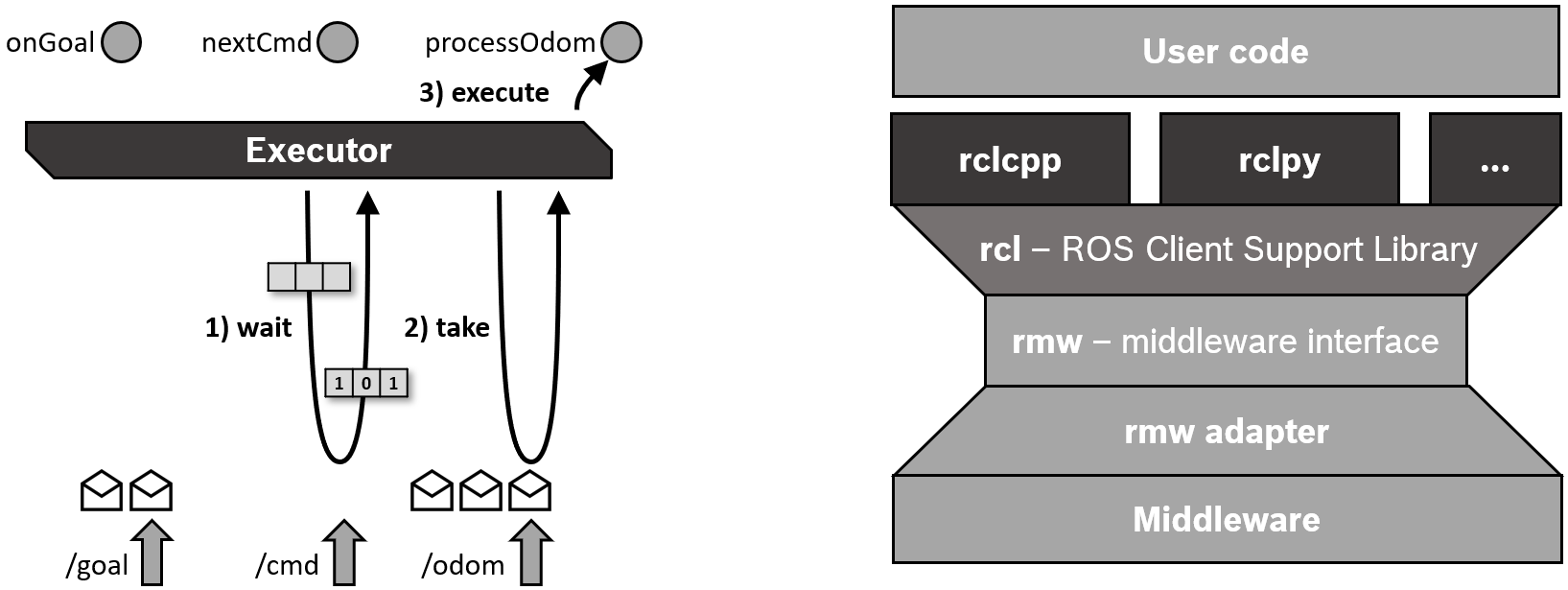
The Single-Threaded Executor is also used by the container process for components, i.e. in all cases where nodes are created and executed without an explicit main function.
Types of Executors
Currently, rclcpp provides three Executor types, derived from a shared parent class:
digraph Flatland { Executor -> SingleThreadedExecutor [dir = back, arrowtail = empty]; Executor -> MultiThreadedExecutor [dir = back, arrowtail = empty]; Executor -> EventsCBGExecutor [dir = back, arrowtail = empty]; Executor [shape=polygon,sides=4]; SingleThreadedExecutor [shape=polygon,sides=4]; MultiThreadedExecutor [shape=polygon,sides=4]; EventsCBGExecutor [shape=polygon,sides=4]; }The Multi-Threaded Executor creates a configurable number of threads to allow for processing multiple messages or events in parallel.
All executors can be used with multiple nodes by calling add_node(..) for each node.
rclcpp::Node::SharedPtr node1 = ...
rclcpp::Node::SharedPtr node2 = ...
rclcpp::Node::SharedPtr node3 = ...
rclcpp::executors::SingleThreadedExecutor executor;
executor.add_node(node1);
executor.add_node(node2);
executor.add_node(node3);
executor.spin();
In the above example, the one thread of a Single-Threaded Executor is used to serve three nodes together. In case of a Multi-Threaded Executor, the actual parallelism depends on the callback groups.
The Callback Group Events Executor
Historically, both the Single and Multi-threaded executors, while simple enough in their implementation and how to reason about their execution, were a significant performance bottleneck.
Available in Lyrical Luth onward, the EventsCBGExecutor is the result of years of work towards reducing the CPU overhead compared to existing executors. Instead of the wait sets, it utilizes a first-in first-out events queue to process ready events. It builds off the core idea that you don't pay for what you're not using, because rather than polling for changes on entities, an entity will enqueue an event to be processed only when it becomes ready.
This new executor improves on its predecessor, the rclcpp::experimental::EventsExecutor, by adding support for multiple sources of ROS time (including sim time), addressing issues with slow running timers leading to a burst of timer events, and multithreading support.
Therefore, the new executor can also act as a drop-in replacement for the MultiThreadedExecutor, as it will also create a configurable number of worker threads to process ready events.
In single-threaded mode, the EventsCBGExecutor results in less context switching and exhibits similar performance characteristics to its predecessor.
Note: Currently, there is no limit to the number of events that can be added to the queue. This means that if the process is overloaded and starts slowing down, the number of ready entities inside the queue can grow unbounded.
rclcpp::Node::SharedPtr node1 = ...
rclcpp::Node::SharedPtr node2 = ...
rclcpp::Node::SharedPtr node3 = ...
rclcpp::Node::SharedPtr node4 = ...
rclcpp::executors::EventsCBGExecutor st_cbg_exec(rclcpp::ExecutorOptions(), 1);
st_cbg_exec.add_node(node1);
st_cbg_exec.add_node(node2);
st_cbg_exec.spin();
rclcpp::executors::EventsCBGExecutor mt_cbg_exec;
mt_cbg_exec.add_node(node3);
mt_cbg_exec.add_node(node4);
mt_cbg_exec.spin();
In the above example, st_cbg_exec will use one thread for processing all of node1 and node2's ready events, while mt_cbg_exec will use the maximum threads available on the system to process node3 and node4's ready events.
Like the Multi-Threaded Executor, the actual parallelism depends on the callback groups when using the CBG Executor with more than one thread.
Callback groups
ROS 2 allows organizing the callbacks of a node in groups.
In rclcpp, such a callback group can be created by the create_callback_group function of the Node class.
In rclpy, the same is done by calling the constructor of the specific callback group type.
The callback group must be stored throughout execution of the node (e.g. as a class member), or otherwise the executor won't be able to trigger the callbacks.
Then, this callback group can be specified when creating a subscription, timer, etc. - for example by the subscription options:
my_callback_group = create_callback_group(rclcpp::CallbackGroupType::MutuallyExclusive);
rclcpp::SubscriptionOptions options;
options.callback_group = my_callback_group;
my_subscription = create_subscription<Int32>("/topic", rclcpp::SensorDataQoS(),
callback, options);
my_callback_group = MutuallyExclusiveCallbackGroup()
my_subscription = self.create_subscription(Int32, "/topic", self.callback, qos_profile=1,
callback_group=my_callback_group)
All subscriptions, timers, etc. that are created without the indication of a callback group are assigned to the default callback group.
The default callback group can be queried via NodeBaseInterface::get_default_callback_group() in rclcpp
and by Node.default_callback_group in rclpy.
There are two types of callback groups, where the type has to be specified at instantiation time:
Mutually exclusive: Callbacks of this group must not be executed in parallel.
Reentrant: Callbacks of this group may be executed in parallel.
Callbacks of different callback groups may always be executed in parallel. The Multi-Threaded Executor uses its threads as a pool to process as many callbacks as possible in parallel according to these conditions. For tips on how to use callback groups efficiently, see Using Callback Groups.
The Executor base class in rclcpp also has the function add_callback_group(..), which allows distributing callback groups to different Executors.
By configuring the underlying threads using the operating system scheduler, specific callbacks can be prioritized over other callbacks.
For example, the subscriptions and timers of a control loop can be prioritized over all other subscriptions and standard services of a node.
The examples_rclcpp_cbg_executor package provides a demo of this mechanism.
Scheduling semantics
If the processing time of the callbacks is shorter than the period with which messages and events occur, the Executor basically processes them in FIFO order. However, if the processing time of some callbacks is longer, messages and events will be queued on the lower layers of the stack. The wait set mechanism reports only very little information about these queues to the Executor. In detail, it only reports whether there are any messages for a certain topic or not. The Executor uses this information to process the messages (including services and actions) in a round-robin fashion - but not in FIFO order. The following flow diagram visualizes this scheduling semantics.
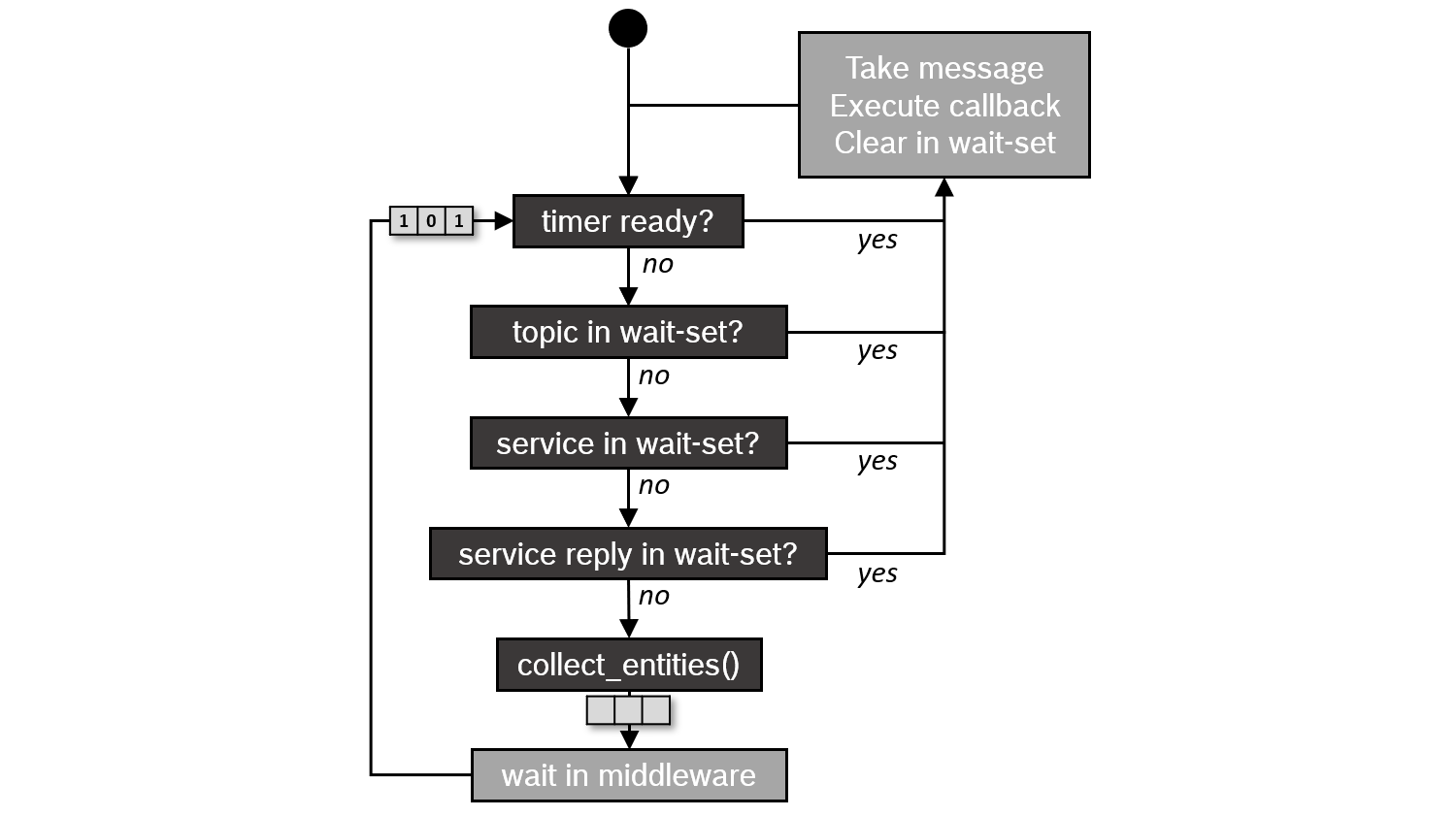
This semantics was first described in a paper by Casini et al. at ECRTS 2019. (Note: The paper also explains that timer events are prioritized over all other messages. This prioritization was removed in Eloquent.)
Outlook
While the Single and Multi-threaded Executors of rclcpp work well for most applications, there are some issues that make them not suitable for real-time applications, which require well-defined execution times, determinism, and custom control over the execution order. Here is a summary of some of these issues:
Complex and mixed scheduling semantics. Ideally you want well defined scheduling semantics to perform a formal timing analysis.
Callbacks may suffer from priority inversion. Higher priority callbacks may be blocked by lower priority callbacks.
No explicit control over the callbacks execution order.
No built-in control over triggering for specific topics.
Additionally, the overhead of the Single and Multi-threaded Executors in terms of CPU and memory usage is considerable.
These issues have been partially addressed by the following developments:
rclcpp WaitSet: The
WaitSetclass of rclcpp allows waiting directly on subscriptions, timers, service servers, action servers, etc. instead of using an Executor. It can be used to implement deterministic, user-defined processing sequences, possibly processing multiple messages from different subscriptions together. The examples_rclcpp_wait_set package provides several examples for the use of this user-level wait set mechanism.rclc Executor: This Executor from the C Client Library rclc, developed for micro-ROS, gives the user fine-grained control over the execution order of callbacks and allows for custom trigger conditions to activate callbacks. Furthermore, it implements ideas of the Logical Execution Time (LET) semantics.
The Callback Group Events Executor utilizes between 10 and 15% less CPU compared to the single and multi-threaded executors, and makes use of a FIFO queue to handle events.
Further information
Michael Pöhnl et al.: "ROS 2 Executor: How to make it efficient, real-time and deterministic?". Workshop at ROS World 2021. Virtual event. 19 October 2021.
Ralph Lange: "Advanced Execution Management with ROS 2". ROS Industrial Conference. Virtual event. 16 December 2020.
Daniel Casini, Tobias Blass, Ingo Lütkebohle, and Björn Brandenburg: "Response-Time Analysis of ROS 2 Processing Chains under Reservation-Based Scheduling", Proceedings of 31st ECRTS 2019, Stuttgart, Germany, July 2019.