分散式通訊#
MLX 支援分散式通訊操作,讓訓練或推論的計算成本能在多台實體機器之間分攤。目前支援數種通訊後端,於下方介紹。
後端 |
描述 |
|---|---|
功能完整且成熟的分散式通訊程式庫。 |
|
在 TCP Socket 上進行 Ring all-reduce 與 all-gather。永遠可用,且通常比 MPI 快。 |
|
透過 Thunderbolt 的 RDMA 低延遲通訊。對張量並行等需求是必要的。 |
|
CUDA 環境的首選後端。 |
目前支援的所有操作及其文件,請參見 API 文件。
開始使用#
在 MLX 中,分散式程式可簡單寫成:
import mlx.core as mx
world = mx.distributed.init()
x = mx.distributed.all_sum(mx.ones(10))
print(world.rank(), x)
上述程式會在所有分散式行程之間對 mx.ones(10) 進行求和。然而用 python 執行此腳本時只會啟動一個行程,因此不會進行分散式通訊。也就是說,當分散式群組大小為 1 時,mx.distributed 中的所有操作都是空操作。這個特性讓我們可以避免寫出需要檢查是否在分散式環境下的程式碼,例如:
import mlx.core as mx
x = ...
world = mx.distributed.init()
# No need for the check we can simply do x = mx.distributed.all_sum(x)
if world.size() > 1:
x = mx.distributed.all_sum(x)
執行分散式程式#
MLX 提供 mlx.launch 這個輔助腳本用來啟動分散式程式。延續前面的範例,我們可以在本機以 4 個行程執行:
$ mlx.launch -n 4 my_script.py
3 array([4, 4, 4, ..., 4, 4, 4], dtype=float32)
2 array([4, 4, 4, ..., 4, 4, 4], dtype=float32)
1 array([4, 4, 4, ..., 4, 4, 4], dtype=float32)
0 array([4, 4, 4, ..., 4, 4, 4], dtype=float32)
我們也可以提供遠端主機的 IP 來執行(前提是腳本在所有主機上都存在,且可透過 ssh 連線)。
$ mlx.launch --hosts ip1,ip2,ip3,ip4 my_script.py
3 array([4, 4, 4, ..., 4, 4, 4], dtype=float32)
2 array([4, 4, 4, ..., 4, 4, 4], dtype=float32)
1 array([4, 4, 4, ..., 4, 4, 4], dtype=float32)
0 array([4, 4, 4, ..., 4, 4, 4], dtype=float32)
更多關於 mlx.launch 的使用方式,請參考專門的 使用指南。
選擇後端#
呼叫 init() 時可以透過 {'any', 'ring', 'jaccl', 'mpi', 'nccl'} 指定要使用的後端。當傳入 any 時,MLX 會嘗試所有可用後端;若全部失敗,則會建立單一成員群組。
備註
分散式後端成功初始化後,再次呼叫 init`(不帶參數或設定為 ``any`())會回傳**相同的後端**。
以下範例用來說明 MLX 中後端初始化的邏輯:
# Case 1: Initialize MPI regardless if it was possible to initialize the ring backend
world = mx.distributed.init(backend="mpi")
world2 = mx.distributed.init() # subsequent calls return the MPI backend!
# Case 2: Initialize any backend
world = mx.distributed.init(backend="any") # equivalent to no arguments
world2 = mx.distributed.init() # same as above
# Case 3: Initialize both backends at the same time
world_mpi = mx.distributed.init(backend="mpi")
world_ring = mx.distributed.init(backend="ring")
world_any = mx.distributed.init() # same as MPI because it was initialized first!
Distributed Program Examples#
Ring 入門#
Ring 後端不依賴任何第三方程式庫,因此永遠可用。它使用 TCP socket,因此節點必須能透過網路互相連線。顧名思義,節點以環狀相連,這表示 rank 1 只能與 rank 0 和 rank 2 通訊,rank 2 只能與 rank 1 和 rank 3 通訊,以此類推。因此 ring 後端不支援任意 sender 與 receiver 的 send() 與 recv()。
定義 Ring#
定義並使用 ring 最簡單的方法,是透過 JSON hostfile 與 mlx.launch 輔助腳本。對每個節點,需定義可 ssh 登入的主機名稱以及一個或多個供其監聽連線的 IP。
例如,以下 hostfile 定義了 4 節點的 ring。hostname1 為 rank 0,hostname2 為 rank 1,以此類推。
[
{"ssh": "hostname1", "ips": ["123.123.123.1"]},
{"ssh": "hostname2", "ips": ["123.123.123.2"]},
{"ssh": "hostname3", "ips": ["123.123.123.3"]},
{"ssh": "hostname4", "ips": ["123.123.123.4"]}
]
執行 mlx.launch --hostfile ring-4.json my_script.py 會 ssh 進入每個節點,並執行腳本、在提供的 IP 上監聽連線。具體來說,hostname1 會連線到 123.123.123.2 並接受來自 123.123.123.4 的連線,以此類推。
Thunderbolt Ring#
即使在乙太網路上,ring 後端也可能優於 MPI,但其主要目的在於使用 Thunderbolt ring 來取得更高頻寬通訊。此類 Thunderbolt ring 可以手動設定,但流程相對繁瑣。為了簡化,我們提供 mlx.distributed_config 工具。
要使用 mlx.distributed_config,你的電腦需能透過乙太網路或 Wi-Fi 以 ssh 連線。接著用 Thunderbolt 線纜連接它們,並如下呼叫工具:
mlx.distributed_config --verbose --hosts host1,host2,host3,host4 --backend ring
預設情況下,腳本會嘗試偵測 Thunderbolt ring,並提供設定各節點的命令,以及可供 mlx.launch 使用的 hostfile.json。若各節點可無密碼 sudo,可使用 --auto-setup 自動完成設定。
如果想手動完成,步驟如下:
停用 Thunderbolt bridge 介面
針對連接 rank
i與 ranki + 1的線纜,在節點i與i + 1上找出對應的介面。為對應介面建立一個專用子網路以連接兩個節點。例如該線纜在節點
i對應en2,且在節點i + 1也對應en2,則可分別配置 IP192.168.0.1與192.168.0.2。更多細節可參考工具腳本準備的命令。
JACCL 入門#
自 macOS 26.2 起,Thunderbolt RDMA 可用,讓搭載 Thunderbolt 5 的 Mac 之間能進行低延遲通訊。MLX 提供 JACCL 後端以利用此功能,其通訊延遲可比 ring 後端低一個數量級。
備註
JACCL(發音 Jackal)代表 Jack and Angelos' Collective Communication Library。這不僅是對 Nvidia NCCL 的雙關,也致敬在 Apple 主導 Thunderbolt RDMA 開發的 Jack Beasley。
啟用 RDMA#
在功能尚未成熟前,啟用 Thunderbolt RDMA 稍嫌繁瑣,且即使有 sudo 也**無法**遠端操作。實際上必須在 macOS 復原模式中完成:
在「工具程式 -> 終端機」開啟 Terminal。
執行
rdma_ctl enable。重新開機。
要確認 Thunderbolt RDMA 已成功啟用,可執行 ibv_devices,在 M3 Ultra 上應會輸出類似以下內容。
~ % ibv_devices
device node GUID
------ ----------------
rdma_en2 8096a9d9edbaac05
rdma_en3 8196a9d9edbaac05
rdma_en5 8396a9d9edbaac05
rdma_en4 8296a9d9edbaac05
rdma_en6 8496a9d9edbaac05
rdma_en7 8596a9d9edbaac05
定義 Mesh#
JACCL 後端僅支援全連接拓撲,也就是每對 Mac 之間都需有 Thunderbolt 線纜直接連接。例如下列拓撲示意中,左圖有效,因為任一節點都能連到任一其他節點;右圖則無效,因為 M3 Ultra 1 沒有連到 M3 Ultra 2。
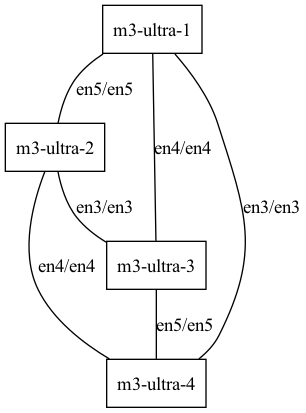
四台 M3 Ultra 的全連接網狀拓撲。
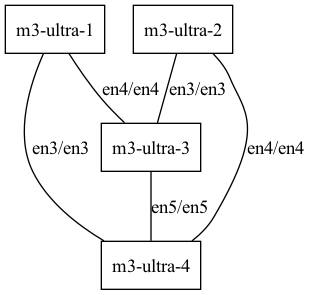
不是有效的網狀拓撲(M3 Ultra 1 未連到 M3 Ultra 2)。
與 ring 後端類似,使用 JACCL 的最簡單方式是撰寫供 mlx.launch 使用的 JSON hostfile。該 hostfile 必須包含:
用於透過 ssh 啟動腳本的主機名稱
所有節點皆可連到的 rank 0 IP
連接各節點彼此的 rdma 裝置列表
以下 JSON 定義了上圖的有效 4 節點網狀拓撲。
[
{
"ssh": "m3-ultra-1",
"ips": ["123.123.123.1"],
"rdma": [null, "rdma_en5", "rdma_en4", "rdma_en3"]
},
{
"ssh": "m3-ultra-2",
"ips": [],
"rdma": ["rdma_en5", null, "rdma_en3", "rdma_en4"]
},
{
"ssh": "m3-ultra-3",
"ips": [],
"rdma": ["rdma_en4", "rdma_en3", null, "rdma_en5"]
},
{
"ssh": "m3-ultra-4",
"ips": [],
"rdma": ["rdma_en3", "rdma_en4", "rdma_en5", null]
}
]
即使 Thunderbolt RDMA 通訊不使用 TCP/IP,仍需停用 Thunderbolt bridge,並為每條 Thunderbolt 連線建立隔離的本地網路。
上述所有步驟也可改由 mlx.distributed_config 完成。此輔助腳本會:
ssh 進入每個節點
取得 Thunderbolt 連線拓撲
檢查是否為有效的 mesh
提供設定各節點的命令(或在有 sudo 時直接執行)
產生供
mlx.launch使用的 hostfile
全部整合#
例如,若節點可透過 ssh 連線且具備無密碼 sudo,啟動使用 JACCL 的分散式 MLX 腳本相當簡單。
首先連接所有 Thunderbolt 線纜。接著使用 mlx.distributed_config 腳本將連線視覺化以進行確認。
mlx.distributed_config --verbose \
--hosts m3-ultra-1,m3-ultra-2,m3-ultra-3,m3-ultra-4 \
--over thunderbolt --dot | dot -Tpng | open -f -a Preview
確認一切正確後,可自動設定各節點並將 hostfile 儲存為 m3-ultra-jaccl.json,執行:
mlx.distributed_config --verbose \
--hosts m3-ultra-1,m3-ultra-2,m3-ultra-3,m3-ultra-4 \
--over thunderbolt --backend jaccl \
--auto-setup --output m3-ultra-jaccl.json
接著就可以執行分散式 MLX 腳本,例如使用 MLX LM 進行巨型模型的分散式推論。
mlx.launch --verbose --backend jaccl --hostfile m3-ultra-jaccl.json \
--env MLX_METAL_FAST_SYNCH=1 -- \ # <--- important
/path/to/remote/python -m mlx_lm chat --model mlx-community/DeepSeek-R1-0528-4bit
備註
設定環境變數 MLX_METAL_FAST_SYNCH=1 會啟用 GPU 與 CPU 之間更快的同步方式。這並非 JACCL 專用,凡是 CPU 與 GPU 需要協同計算的情況都可使用,且因通訊由 CPU 執行,對低延遲通訊而言相當關鍵。
開始使用 NCCL#
MLX 在 CUDA 環境中可與 NCCL 通訊。NCCL 是高效能的集合通訊程式庫,支援多 GPU 與多節點設定。
在 CUDA 環境中,NCCL 是 mlx.launch 的預設後端,要啟動分散式工作只需:
mlx.launch -n 8 test.py
# perfect for interactive scripts
mlx.launch -n 8 python -m mlx_lm chat --model my-model
你也可以用 mlx.launch 透過 ssh 連到遠端節點並同樣輕鬆地啟動腳本
mlx.launch --hosts my-cuda-node -n 8 test.py
在許多情況下你可能不會想用 mlx.launch 搭配 NCCL 後端,因為叢集排程器會負責啟動行程。你可以 查看需要設定的環境變數,以便正確初始化 MLX 的 NCCL 後端。
開始使用 MPI#
若機器上已安裝 MPI,MLX 便可與其通訊。使用 MPI 的分散式 MLX 程式可如預期透過 mpirun 啟動。不過在以下範例中,我們使用 mlx.launch --backend mpi,它會處理一些細節,例如為 mpirun 可執行檔與 libmpi.dyld 共享程式庫設定絕對路徑。
最簡單的用法如下,假設使用本頁開頭的最小範例,輸出應為:
$ mlx.launch --backend mpi -n 2 test.py
1 array([2, 2, 2, ..., 2, 2, 2], dtype=float32)
0 array([2, 2, 2, ..., 2, 2, 2], dtype=float32)
以上會在同一台(本地)機器上啟動兩個行程,並可看到兩個標準輸出。行程會互相傳送全 1 陣列並計算總和後印出。若使用 mlx.launch -n 4 ... 則會印出 4,依此類推。
安裝 MPI#
MPI 可透過 Homebrew、pip、Anaconda 軟體包管理器安裝,或從來源碼編譯。我們大多數測試使用 Anaconda 軟體包管理器安裝的 openmpi:
$ conda install conda-forge::openmpi
透過 Homebrew 或 pip 安裝時,需要指定 libmpi.dyld 的位置,讓 MLX 能在執行時找到並載入它。這可透過將 DYLD_LIBRARY_PATH 環境變數傳給 mpirun 來達成,而 mlx.launch 會自動完成。某些環境使用非標準的程式庫檔名,可用 MPI_LIBNAME 環境變數指定,mlx.launch 同樣會自動處理。
$ mpirun -np 2 -x DYLD_LIBRARY_PATH=/opt/homebrew/lib/ -x MPI_LIBNAME=libmpi.40.dylib python test.py
$ # or simply
$ mlx.launch -n 2 test.py
設定遠端主機#
若可透過 ssh 連線到遠端主機,MPI 便可自動連線並建立網路通訊。以下是排查連線問題的檢查列表:
所有機器之間執行
ssh hostname不需密碼或主機確認所有機器皆可存取
mpirun。請確保 MPI 使用的
hostname與所有機器.ssh/config中設定的一致。
調校 MPI All Reduce#
備註
若要更快的 all-reduce,可考慮使用 ring 後端(透過 Thunderbolt 連線或乙太網路)。
透過 --mca btl_tcp_links N 設定 MPI 在每個主機間使用 N 條 TCP 連線,以提升頻寬。
透過 --mca btl_tcp_if_include <iface> 強制 MPI 使用效能最佳的網路介面,其中 <iface> 為你想使用的介面。
不使用 mlx.launch 的分散式#
分散式後端的實作並不強制使用 mlx.launch。該腳本只是連線到各主機、為每個 rank 啟動一個行程,並在移交給你的 MLX 腳本前設定必要的環境變數。詳情請參考 專門文件頁。
在許多使用情境下,這會是最簡單的 MLX 分散式計算方式。然而,有時你可能無法或不應使用 mlx.launch。常見例子是使用排程器,在排程時尚未確定的機器上為你啟動所有行程。
以下列出各後端所需的環境變數。
Ring#
MLX_RANK 應包含一個以 0 為起始的整數,用於定義行程的 rank。
MLX_HOSTFILE 應包含一個 json 檔路徑,其中列出各 rank 要監聽的 IP 與連接埠,例如:
[
["123.123.1.1:5000", "123.123.1.2:5000"],
["123.123.2.1:5000", "123.123.2.2:5000"],
["123.123.3.1:5000", "123.123.3.2:5000"],
["123.123.4.1:5000", "123.123.4.2:5000"]
]
MLX_RING_VERBOSE 為選用,設為 1 時會啟用更多分散式後端的日誌輸出。
JACCL#
MLX_RANK 應包含一個以 0 為起始的整數,用於定義行程的 rank。
MLX_JACCL_COORDINATOR 應包含 rank 0 監聽的 IP 與埠號,供其他 rank 連線建立 RDMA 連線。
MLX_IBV_DEVICES 應包含一個 json 檔路徑,其中列出連接各節點彼此的 ibverbs 裝置名稱,例如:
[
[null, "rdma_en5", "rdma_en4", "rdma_en3"],
["rdma_en5", null, "rdma_en3", "rdma_en4"],
["rdma_en4", "rdma_en3", null, "rdma_en5"],
["rdma_en3", "rdma_en4", "rdma_en5", null]
]
NCCL#
MLX_RANK 應包含一個以 0 為起始的整數,用於定義行程的 rank。
MLX_WORLD_SIZE 應包含將啟動的行程總數。
NCCL_HOST_IP 與 NCCL_PORT 應包含所有主機可連線以建立 NCCL 通訊的 IP 與埠號。
CUDA_VISIBLE_DEVICES 應包含對應此行程的 GPU 本地索引。
當然,NCCL 使用的 其他環境變數 也可設定。
技巧與提示#
這裡提供一些小技巧,協助你更好地運用 MLX 的分散式通訊能力。
先在本機測試。
你可以用
mlx.launch -n2 -- my_script.py的模式先在單一節點做小規模測試。批次化通訊。
如 訓練範例 所述,進行大量小型通訊會影響效能。可參照
mlx.nn.average_gradients()的做法,把多次小通訊聚合成一次大型通訊。視覺化連線。
使用
mlx.distributed_config --hosts h1,h2,h3 --over thunderbolt --dot來視覺化連線,確認線纜正確連接。範例請參考 JACCL 章節。使用除錯器。
mlx.launch用於互動式操作。它會將 stdin 廣播到所有行程並收集各行程的 stdout,讓使用pdb變得很容易。